Predictive model in dairy sector
Abstract
Les acteurs du domaine agricole sont continuellement
contraints de prendre des décisions économiques visant à faire prospérer leur
activité. En effet, la capacité d’un
animal d’élevage à générer un profit est un critère essentiel pour l’éleveur.
Ce dernier doit continuellement évaluer la capacité de sa bête à produire une
certaine quantité de matière première dont le coup de vente doit excéder les
dépenses engendrées pour maintenir l’animal prospère et en bonne santé.
Ici nous présenterons une approche basée sur un modèle
statistique ayant pour but d’assister les fermiers dans leurs décisions
d’investissements concernant leurs vaches laitières. En effet certains modèles
ont été mis au point dans le but d’estimer la profitabilité d’un animal en
prenant en compte un certain nombre de facteurs de risques. Maxime Radmacher est un ingénieur de recherche en bioinformatiques
de l’UQAM, ses travaux portent sur l’utilisation de réseaux de neurones
récurrents ainsi que des modélisations non linéaires pour prédire la rentabilité
de production laitière d’un animal donné.
Introduction
Un unique animal tel qu’une vache laitière peut être à
l’origine de nombreux investissements pour un agriculteur. Le coût de
l’insémination et les tests de grossesse s’ajoutent ainsi à l’entretien de
l’animal tel que les soins qui sont réalisés, l’alimentation de l’animal, et
plus généralement sa valeur monétaire globale (salaires des employés, coût de
stockage dans les locaux, etc.). Néanmoins il est difficile pour l’éleveur
d'estimer à l’avance si le bénéfice généré par la revente du lait de la vache
viendra surpasser les dépenses engendrées pour aboutir à cette production de
lait. Il faut ainsi prendre en compte qu’une vache laitière ayant atteint sa
maturité sexuelle passera la majeure partie de sa vie à être inséminée
artificiellement de façon successive pour la placer dans des dispositions ou cette dernière produit du lait. La gestation s’étalant sur 9
mois il est donc important pour l’éleveur de ne pas procéder à l’insémination
d’une vache puis à son entretien si ce n’est pas pour que cette dernière soit
en mesure de rendre une bonne production laitière. Les approches algorithmiques
d’apprentissage machine peuvent ainsi répondre efficacement au besoin de
génération de modèles pouvant assister les professionnels dans des décisions
relatives à leurs investissements. Maxime Radmacher a
ainsi généré un modèle prenant en compte de nombreuses variables génomiques, phénomiques et environnementales afin de créer un
algorithme robuste et facile d’utilisation pour les éleveurs de vaches
laitières.
Méthode
- Découverte des données
Quelle que soit l’application envisagée, la première
étape consiste nécessairement à explorer les données fournies pour la
réalisation du modèle. L’informaticien ou analyste se fait ainsi confier une
quantité importante de ces données qui peuvent être présentées sous divers
formats.
- Comprendre la problématique
La première phase du travail est une des plus
importantes, elle consiste à comprendre la problématique et la formuler
correctement. C’est généralement lors de cette phase que l’expert en charge de
l’analyse pourra se rendre sur le terrain et échanger avec les professionnels à
l’origine des données générées. L’expert pourra ainsi à la fois pleinement
assimiler son sujet mais également éliminer certains biais potentiels à travers
des observations ou des échanges. Comme Maxime l’a fait remarquer, cette étape
d’appréhension de l’environnement d’étude est également cruciale dans le sens
où elle permet de construire la dimension éthique du sujet. Nous discuterons en
conclusion de ces dernières. Dresser correctement la problématique est crucial.
En effet une problématique mal comprise ou maladroitement formulée peut
conduire à des biais importants lors de l’investigation. Il est important
d’être conscient des dangers qui se posent lorsque l’on traite le sujet en
commençant par poser la problématique puisque celle-ci délimite le cadre dans
lequel s'inscrit l’étude et ainsi les limites du sujet.
Pour Maxime la problématique consiste à savoir s’il
est économiquement intéressant pour l’éleveur que de réinséminer
sa vache après une première lactation. Cette problématique se pose ainsi après
chaque cycle de récupération du lait de l’animal, ces cycles sont présentés sur
la figure suivante.
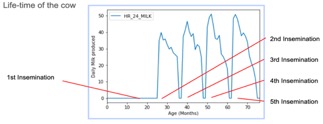
Figure
1 : Cycle de vie des vaches laitières, la première insémination a lieu
après 24 mois, les suivantes sont éventuellement réalisées en fonction de la
décision de l’éleveur. Schéma tiré de la présentation de Maxime.
- Concevoir l’approche
Une fois les limites du sujet et la problématique
dressées, il convient de planifier la façon dont l’étude sera réalisée. On
dresse ainsi un workflow des différentes étapes de la réalisation du projet. On
y retrouve ainsi les différentes étapes de traitement des données ainsi que des
analyses qui seront réalisées sur ces dernières. Bien entendu le but ici est de
réaliser un modèle qui soit à la fois fidèle, robuste et répondant à la demande
des professionnels démarchant l’étude. On se doit ainsi de trouver une méthode
qui réalisera la meilleure approximation possible avec le minimum de complexité.
Dans le cas du modèle développé par Maxime, il a été
décidé une fenêtre temporelle de la vie de l’animal pour mettre au point le
modèle. Cette période s’étend de la naissance jusqu’à 5 ans, en sachant que la
moyenne de première lactation est de 24 mois après la naissance de l’animal,
moment où elle obtient son premier enfant. Par la suite, si elle a lieu,
l’insémination sera mise en place tous les 12 à 15 mois, avec une période de
gestation de 9 mois. Tout au long de leur vie des tests sont ainsi réalisés sur
la vache, en moyenne une vingtaine seront réalisés lors de la vie de l’animal.
Ces données sont computées par le modèle afin
d’évaluer le futur profit en cas de seconde lactation ou si au contraire il
sera nécessaire de revendre ou abattre l’animal. Le modèle choisi est un modèle
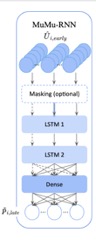
dit de “forecasting” appelé seq2seq modeling, il est réalisé à partir d’un réseau de neurones
récurrents (RNN) avec une dynamique de machine learning.
Cet algorithme en particulier est dit avec LSTM, pour “long short-term memory”, ce qui signifie que par opposition aux RNN
unidirectionnels (feedforward neural networks),
le réseau possède des connexions de rétroaction. Comme présenté sur la figure
2, les informations sortantes permettent de nourrir le réseau et ainsi de
l’enrichir, l’algorithme s’implémente en “apprenant”.
- Extraction et sélection des données
Il faudra alors dans un premier temps sélectionner les
paramètres les plus perspicaces pour la réalisation du modèle. Pour le cas du
modèle de Maxime on peut noter certaines variables de haute importance telles
que des paramètres  environnementaux : température ou
date, des paramètres propres aux différents managements de la vache : fréquence
de traite, durée de traite, nombre de lactation, nombre de jours de lactation,
des paramètres de production : lait, protéines, graisse, lactose, ainsi que la
valeur du lait, et enfin des paramètres concernant l’état de santé de l’animal
sur la base de différents marqueurs : compte de cellules somatiques ou
concentration d’urée dans le lait. Ce dernier paramètre reflète un potentiel
excès d’ammonium car un excès de ce dernier est converti en urée. Cet excès
reflète un problème d’absorption du nitrate à partir de l’ammonium (NH₄⁺) au
niveau du rumen de l’animal, et ainsi un déséquilibre des protéines
nutritionnelles de l’animal. Une fois les critères sélectionnés il convient
d’extraire les données judicieusement afin que leur organisation soit propice à
l’exploitation en découlant. Ces dernières peuvent ainsi être réparties en une
ou plusieurs matrices.
environnementaux : température ou
date, des paramètres propres aux différents managements de la vache : fréquence
de traite, durée de traite, nombre de lactation, nombre de jours de lactation,
des paramètres de production : lait, protéines, graisse, lactose, ainsi que la
valeur du lait, et enfin des paramètres concernant l’état de santé de l’animal
sur la base de différents marqueurs : compte de cellules somatiques ou
concentration d’urée dans le lait. Ce dernier paramètre reflète un potentiel
excès d’ammonium car un excès de ce dernier est converti en urée. Cet excès
reflète un problème d’absorption du nitrate à partir de l’ammonium (NH₄⁺) au
niveau du rumen de l’animal, et ainsi un déséquilibre des protéines
nutritionnelles de l’animal. Une fois les critères sélectionnés il convient
d’extraire les données judicieusement afin que leur organisation soit propice à
l’exploitation en découlant. Ces dernières peuvent ainsi être réparties en une
ou plusieurs matrices.
- Pré-processing des données
Les matrices vont être soumises à une réorganisation
afin que ces dernières puissent être lues dans l'interface de codage, en
l'occurrence sur Python. Par la suite il convient de réaliser les premiers tests
statistiques. En effet il est important de prendre en considération le fait que
les jeux de données fournis contiennent généralement de nombreuses valeurs
aberrantes. Ces valeurs sont ainsi celles qui contrastent grandement avec les
valeurs “normalement” mesurées. S’ajoute à cela des données que l’on doit
écarter de l’analyse comme ici le fait que les vaches n’ayant pas produits de
lait présentent une production de 0 litre et non une production “inexistante”,
on se retrouve donc avec un impact important sur la moyenne et la médiane alors
que l’on souhaite uniquement à s’intéresser aux animaux suffisamment matures pour
produire du lait (figure 3).

Figure
3 : distribution des données de Maxime. On note que la médiane est
déplacée vers la gauche car les vaches laitières n'ayant pas produit de lait
présentent une valeur de 0, ces valeurs doivent être enlevées.
On constate un décalage important de la moyenne alors
que les vaches ne produisant pas encore de lait ne devraient pas impacter la
distribution des vaches productrices de lait.
Ces procédés statistiques sont très conventionnels et
consistent ainsi à écarter le plus possible les données qui tendent à fausser
les informations utilisées par le modèle. La deuxième étape consiste à rogner
les bornes extrêmes, ce seuil n’est pas conventionnel, il dépend du choix de
l’analyste et constitue généralement un quantile de 0,5 à 2% de la
distribution.
La dernière étape de pré-processing
consiste à combler les trous dans les données, en effet il est quasi-impossible
d’obtenir un jeu de données ne contenant aucune valeur manquante ou série de
valeurs manquantes. Il convient ainsi de trouver une méthode adaptée permettant
un “padding”, c’est à dire un remplissage des données
manquantes. Ce dernier peut être réalisé de plusieurs façons telles que par une
interpolation linéaire, de moyenne, de valeur (en choisissant une valeur,
généralement négative, pour ces données manquantes) ou encore une interpolation
composite qui permet de remplir les données manquantes à l’aide de plusieurs
paramètres. Cette fonction du package panda permet d’utiliser un combiné de
plusieurs techniques d’interpolation comme par exemple de fixer un seuil
d’interpolation linéaire en dessous duquel le gap sera rempli par une valeur
négative.
- Diviser les données et évaluer le modèle
- Isolat du t-test
Une fois les données prêtes à être utilisées il
convient d’isoler une certaine proportion du jeu de données dans le but de
venir tester la fiabilité du modèle une fois ce dernier entraîné et ainsi
opérationnel. Il n’existe ainsi pas de proportion conventionnelle, cette
fraction de données que l’on se réserve dépend du choix de l’analyste, en
revanche il est courant de sélectionner 30% des dernières valeurs. Ces données
sont mises de côté.
- Entrainement du modèle
Le reste des données, hors
t-test, sont utilisées pour procéder à la phase d'entraînement du modèle. Pour
cette étape il convient d’utiliser une bibliothèque d’apprentissage machine du
type de réseau choisi, en l'occurrence de réseau de neurones. Maxime a ainsi
choisi de travail à partir de la bibliothèque en open access
créé par Google appelée Keras (Chollet F., 2015).
L'entraînement se fait en deux étapes de passage forward puis backward. On génère
dans un premier temps des données de sortie (output) à partir des données
d’entrée (passage vers l’avant), puis le modèle fait passer les données de
sortie dans le sens inverse dans le but d’essayer de retomber sur les données
des couches alternatives (hidden layers),
ce phénomène s’appelle la backpropagation. De cette
manière le modèle est capable d’ajuster le poids de chaque connexion afin de
s’affiner.

Figure 4 : Schéma représentatif de l’entrainement en deux étapes d’un modèle de type réseau de neurones.
Il est possible de faire un test de validation croisée
lorsque celui-ci est en cours d'entraînement, la méthode est décrite dans la suite
de ce rapport. Le but est ainsi de confirmer que l’on obtient les mêmes types
résultats et que l'entraînement du modèle est ainsi efficace.
Il est important de veiller aux capacités du modèle,
en effet un modèle avec trop peu ne pourra pas apprendre correctement tandis
qu’un modèle avec trop de capacité pourra au contraire subir un phénomène de surajustement (ou surapprentissage)
ce qui aboutira à une mauvaise analyse de données futures. On aura ainsi un surajustement si la tendance de la perte de validation se
montre supérieure à la tendance de la perte d'entraînement, en effet on cherche
au contraire un équilibre entre ces deux tendances.
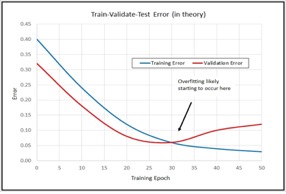
Figure
5 : Schéma représentatif d’un surajsutement
lors de la phase d’entrainement du modèle.
- Évaluation et test du modèle
La dernière étape consiste à évaluer le modèle en
analysant la distribution des donnés de sortie de l’algorithme, il est
important de ne retrouver qu’une seule population qui atteste de la fiabilité
du modèle généré. Afin de le confirmer il faut tester le modèle avec les
données du t-test mises de côté au préalable.
Application à partir d’un
nouveau jeu de données
Suite à cette analyse du travail de Maxime basé l’utilisation
de modèles de séries temporelles (Time-series forecasting) pour prédire la production laitière, nous
avons cherché à explorer la possibilité d’appliquer sa stratégie de recherche à
une autre thématique. Nous nous sommes ainsi intéressés à la prédiction des
rendements agricoles à travers la gestion d’un parasite en particulier : Phytophtora infestans, un mildiou de la pomme
de terre. L’objectif est ainsi d’analyser un autre jeu de données d’en tirer un
principe, des caractéristiques, des champs d’applications et ainsi de clarifier
chaque étape de la stratégie utilisée par Maxime.
1. Découverte des données

Figure
6 : En haut : culture de pomme de terre, en bas : lésion sur la surface
foliaire d’un pied de pomme de terre infection de Phytophtora infestans
Le
jeu de donnés à notre disposition vient d’une étude portant sur l'évaluation de
la résistance au mildiou en 2015. 919 échantillons qui viennent de 307 lignées
de pomme de terre ont ainsi été cultivées (10 plantes pour chaque échantillon)
dans des zones de haute altitude (2670m) de la province du Yunnan, en Chine.
Selon des symptômes caractéristiques connus et documentés, les chercheurs ont
déterminé manuellement la zone des lésions en pourcentage de la surface
foliaire totale. La première détermination a eu lieu à la cinquante-troisième
journée après l’émergence de semis. À compter de cet instant, le pourcentage de
lésion a été déterminé 8 fois de suite à une fréquence d’une fois par semaine.
Aucun produit phytosanitaire n’a été utilisé sur ces cultures. Les données de
rendement sont déterminées à la fin de la culture. Il est important de noter
que dû à une non-divulgation de la part de l’institut en charge de l’étude, les
informations de rendement pour seuls 529 échantillons des 919 nous ont été
communiqués (nombre de tubercules et poids de ces derniers). En revanche les
données concernant les lésions dues au parasite sont divulguées pour les 919
échantillons. Le choix de ces 529 échantillons n’a aucun lien avec les
résultats et nous avons ainsi admis que cela ne causait pas de biais. En somme,
les variables de haute importance sont : le pourcentage de lésion pendant la
période de reproduction (déterminations à 8 instants t pour 919 échantillons),
le nombre de tubercules par plante (529 échantillons) et le poids du tubercule
par plante (529 échantillons).
2. Comprendre la problématique
En tant que la quatrième
culture la plus produite dans le monde, la production et les maladies de la
pomme de terre sont toujours les sujets préoccupants. Parmi les maladies de la
pomme de terre, le mildiou (Phytophtora infestans) est dommageable, particulièrement en Chine,
le pathogène est également connu pour avoir été à l’origine de certaines
grandes famines européennes du milieu du 19ème siècle comme en Irlande ou en
Ecosse (Ristaino, J. et al., 2001). Le mildiou est
provoqué par Phytophtora infestans qui
sont des mycètes à la classe des oomycètes (Fry, W., 2008). Les symptômes d’une
infection par ce mildiou présentent l’apparition de feuilles brunes nécrosées
et un épiderme de tubercules avec des taches brunes. À un stade d’infection
avancé, une pourriture importante sera peut conduire à une destruction totale
de la tubercule (Verscheure, 2017). Compte tenu de
ces symptômes précédents ce stade de destruction plus ou moins important, il
pourrait être intéressant de mettre au point une méthode pouvant prédire les
rendements finaux de la culture en déduisant la gravité de la maladie aux
stades moyen et tardifs de l’infection. Il serait possible de mettre au point
cet algorithme de prédiction par le biais d’un modèle de séries temporelles. En
théorie un modèle efficace permettrait une gestion plus précise de ces cultures
infectées qui pourrait restreindre l’utilisation abusive de produits
phytosanitaires.
3. Concevoir l’approche
Comme décrits par Maxime, les
modèles autorégressifs à moyenne mobile intégrée (Autoregressive
integrated moving average, ARIMA) et de réseaux de neurones récurrents (Recurrent Neural Network,RNN)
sont les deux principaux dans les modèles de séries temporelles. La première
problématique est donc de savoir si ces deux modèles peuvent répondre à notre
mission consistant à réaliser un outil de prédiction de la résistance de
cultures de pommes de terre face à Phytophtora
infestans.
Nous voulons également pouvoir être en mesure de déduire le rendement par la
performance dès la 4ème semaine de culture après apparition des semis.
ARIMA appartient aux modèles
de séries statistiques univariées. Il est utilisé
pour prédire les valeurs futures sur la base des valeurs observées au
préalable. Il analyse les données de séries chronologiques pour en extraire des
statistiques significatives. Bien que cela soit conforme à nos objectifs
d’analyse, ce modèle ne peut pas être appliqué à nos données car les données de
l’ARIMA doivent être stationnaires, ce qui n’est pas notre cas ici. En effet
une série de données est dite stationnaire quand sa moyenne et variance sont constantes
dans le temps (Sato, R. C., 2013). Ce n’est pas notre
cas ici comme on constate une augmentation des critères sélectionnés pour
l’étude (pourcentage de lésion). En outre, il faut que la matrice de covariance
et variance ne dépende pas du temps. Nos données n’étant pas stationnaires il
existe certes des algorithmes spéciaux qui peuvent transformer des données
plusieurs fois pour arriver à cette forme, mais qui induiraient ici un biais et
des complications trop importantes.
L’ARIMA n’est donc pas un bon choix pour nos données.
![]()
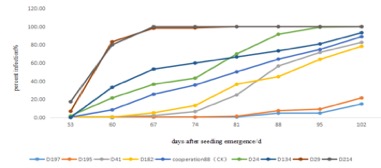
Figure
7 : Représentation de la non-constance de la variante du pourcentage
d'infection des plants de pomme de terre. On constate en effet une évolution
non linéaire qui illustre l'impossibilité d'utiliser le modèle ARIMA.
Sur
la figure ci-dessus on constate en effet que la variante de pourcentage
d’infection n’est pas constante et ainsi non adaptée à une analyse avec ARIMA.
D’autre
part, RNN appartient aux modèles de réseau de neurones. En comparaison de
l’ARIMA, la stationnarité n'est pas une exigence. Il est formé par des couches
de nombreuses transformations non linéaires. En comparaison des autres types de
réseau de neurones, par exemple Feed-Forward Network,
RNN est capable de mémoriser l’output passé. C’est la raison pour laquelle le
modèle RNN est fréquemment utilisé sur l’analyse de séries temporelles.
Néanmoins il est important de noter que le modèle admet également des limites
comme une “explosion de gradient”. Ceci peut avoir lieu pendant l'entraînement
du modèle et consiste en une accumulation de gradients d'erreur qui peuvent
entraîner de grandes mises à jour dans le poids des connexions du modèle de
réseau neuronal. C’est donc le phénomène de back propagation qui est ici à
l’origine de la limite principale de ce modèle. Pour résoudre ce problème, LSTM
(long short-term memory) est utilisé par Maxime dans
ses recherches.
LSTM
est un type particulier de RNN. Il est capable d'apprendre des dépendances à
long terme. Par conséquent, LSTM peut décider dans quelle mesure le passé doit
se souvenir, combien cette unité devrait ajouter à l'état actuel et quelle
partie de l'état actuel doit arriver en output. Compte tenu de la petite
quantité de nos données, et pour résoudre le problème du gradient disparaissant
(vanishing gradient : poids des connexions diminuant
de façon trop importante, ce phénomène est également dû à la backpropagation), LSTM peut être un modèle candidat.
Toutefois, il est important de faire un diagnostic de modèle pour assurer que
l'hypothèse est satisfaisante. En revanche pour utiliser le modèle LSTM pour
notre cas pratique, il faut utiliser un package permettant de respecter un
ordre chronologique dans nos données.
4. Extraction et sélection des données
Selon
le but d’analyse, certains paramètres non directement liés à la maladie ne sont
pas inclus dans l'analyse. Par exemple, couleur de tige, couleur de feuille,
couleur de fleur, forme de tubercule, couleur d’épiderme, condition des
bourgeons, etc. In fine, nos
variables de haute importance sont : <1> pourcentage de lésion pendant la
période de reproduction pour étudier le développement du pathogène
(détermination à 8 instants t hebdomadaires à compter de l’émergence des semis
pour les 919 échantillons). <2> nombre de tubercules par plante (529
échantillons). <3> poids du tubercule par plante (529 échantillons). Ceci
dans le but d’étudier l’impact de la maladie sur le rendement.
5. Pré-processing des données
Dans
notre cas, les mesures manquantes sont dues au mélange de semence ou à
l’émergence irrégulière d’une infection par le parasite oomycète. Bien que certains
algorithmes puissent automatiquement déduire les valeurs manquantes nous avons
décidé de supprimer les valeurs manquantes.
La
normalisation est également une étape importante dans la procédure de pré-processing, nous avons besoin que tous les attributs
numériques de notre ensemble de données soient compris entre 0 et 1 (ou entre
-1 et 1). La normalisation Min-Max qui est utilisée dans la recherche de Maxime
est une transformation linéaire. La normalisation Min-Max transforme la valeur
originale (A) en une nouvelle valeur A’ en prenant en compte les valeurs
maximales et minimales de cet attribut :
![]()
Dans
notre cas, il est difficile de connaître exactement les valeurs maximales et
minimales. Afin d’éviter la possibilité d’avoir des valeurs en dehors de
l’intervalle souhaité, le Z-score est une méthode efficace pour normalisation.
Au lieu de se référer aux valeurs maximales et minimales, le Z-score va
permettre de centrer les données sur la moyenne. De cette manière les données
auront un écart type de 1. Par ailleurs, il est important de noter que le
Z-score suppose que les données sont normalement distribuées. Ainsi avant
d’utiliser cette méthode il est important de vérifier que les données sont
normalement distribuées, ceci peut être simplement réalisé à l’aide d’un test
de normalisation. Dans le cas contraire des techniques de normalisation non
linéaires peuvent être envisagées. On aura ainsi le softmax,
le sigmoid etc.
![]()
6. Diviser les données et évaluer le modèle
Au
lieu de diviser les données de manière à obtenir un set d'entraînement du
modèle, un set de validation croisée et un set test comme décrit dans les
méthodes, Maxime applique la méthode validation croisée de k-fold pour remplacer le set de données de validation
croisée. Cette validation croisée par k-fold est une
stratégie permettant de valider certains paramètres du modèle, particulièrement
quand la quantité de données est limitée. Ce test semble ainsi être une
meilleure option pour notre cas.
Les
étapes de k-fold cross-validation sont :
<1>
Diviser les données disponibles en set d'entraînement et set de test.
<2>
Diviser le set d'entraînement en k-folds
<3>
Basé sur différentes combinaisons de k-folds, le set
d'entraînement est divisé en de nouveaux sets d'entraînement et de test.
Par
exemple, si K=4 :
|
K=4 |
test |
Training data |
Test data |
|
|
1 |
Fold 2, Fold
3, Fold4 |
Fold 1 |
|
2 |
Fold 1, Fold
3, Fold4 |
Fold 2 |
|
|
3 |
Fold 1, Fold
2, Fold4 |
Fold 3 |
|
|
4 |
Fold 1, Fold
2, Fold3 |
Fold 4 |
<4>
Selon le résultat des validation (tests), sélectionner le meilleur modèle (ou
paramètre)
Par
manque de place, l’analyse à partir de notre jeu de données sera présentée lors
de la présentation finale, elle est réalisée en codage python à partir du
package PANDA.
Discussion
Selon Maxime, l’organisation des données et leur
classification, c’est à dire poser la problématique et choisir l’approche,
constituent 90% du temps accordé par le data scientist
à son analyse. Effectivement nous pouvons noter que les choix d’importance capitale
résident avant tout dans l’organisation des données dont le choix des variables
et dans un second temps dans le choix des méthodes de pré-processing
et d’apprentissage machine choisies. De ce fait il est important de justifier
ces choix.
Concernant l’analyse sur notre jeu de données
plusieurs points sont à mettre en avant :
<1> Même si les but de recherche sont
similaires, il est possible de ne pas pouvoir utiliser la même stratégie
d’analyse. Il faut ainsi analyser les caractères de données. L’ARIMA et la
normalisation Min-Max ne sont pas pertinents dans notre cas.
<2> Il est nécessaire de faire un diagnostic du
modèle pour s’assurer que l'hypothèse est satisfaisante. La validation croisée
avec k-fold est une stratégie efficace pour un jeu de
données limité.
<3> Pour bien étudier le développement de ce
mildiou et l’impact de la maladie sur le rendement, les données dans notre cas
présentent de nombreuses limitations. Premièrement, il serait possible
d’utiliser une caméra d'imagerie hyperspectrale afin d’augmenter
la précision des données. Deuxièmement, une série importante d’attributs
associés à cette infection n'ont pas été déterminés tels que les paramètres
climatiques, la densité de plantation, l'humidité du sol, etc. Ces derniers
pourraient en théorie être ajoutés à l'étude afin d'accroître considérablement
la fiabilité du modèle ainsi que sa robustesse. Pour finir, les données
seraient nettement plus exploitables si elles contenaient des critères sur
plusieurs années et ainsi dans différents contextes environnementaux.
Par opposition, le jeu de Maxime est d’excellente
qualité. On peut ainsi noter un panel bien plus important de variables
disponibles dans un premier temps. De plus on peut mettre en avant une extrême
régularité dans le traitement des animaux, qui a été confirmé par les
observations de Maxime sur le terrain, et qui assure un jeu de données homogènes.
Les animaux subissent ainsi exactement les mêmes traitements et la même
alimentation, ce qui n’est pas nécessairement le cas pour d’autres jeux de
données, mais donne ici de la crédibilité au modèle de Maxime.
Conclusion/ouverture
Les modèles statistiques basés sur une approche
d’apprentissage machine peuvent se montrer extrêmement utile afin de réaliser
la prédiction de tendances. Ceci peut être mis en application pour de nombreux
problèmes.
Un point crucial soulevé par Maxime est la dimension
éthique d’une approche informatique de ce type. En effet il y a une
responsabilité scientifique de l’expert à l’origine du modèle. Ce dernier doit
rester réaliste dans sa complexité d’utilisation : il faut prendre en compte
qui va l’utiliser, comment, les paramètres requis pour le faire fonctionner, et
surtout la stabilité de l’environnement pour lequel il va être utilisé, en
effet la robustesse du modèle dépend aussi grandement de sa pérennité. De plus,
et c’est le cas pour tout type de problématique scientifique, il est crucial de
prendre en compte les inégalités sociales d’un tel questionnement scientifique.
En effet on peut se demander si le modèle généré va pouvoir profiter les
populations qui en auraient le plus besoin. Ont-elles
les infrastructures ou les terminaux suffisants pour faire runner
ce type d’algorithme ? Est-il au contraire trop compliqué en termes de
puissance de calcul nécessaire ? Il est également important de prendre en
considération le contexte international actuel dans lequel va s’inscrire
l’application aidée par ce modèle, on parle ici du changement climatique. Le
modèle va t’il s’inscrire dans une démarche raisonnée et écologique de nourrir
la planète tout en préservant nos écosystèmes ou au contraire dans le sens
d’une surconsommation massive allant à l’encontre de la biodiversité.
Bibliographie
Chollet, F. (2015). keras. GitHub. https://github.com/fchollet/keras.
Fry, W. (2008). Phytophthora infestans: the plant (and R gene) destroyer. Molecular plant pathology, 9(3),
385-402.
Ristaino,
J. B., Groves, C. T., & Parra, G. R. (2001). PCR amplification of the Irish
potato famine pathogen from historic specimens. Nature, 411(6838), 695-697.
Sato, R. C. (2013). Disease
management with ARIMA model in time series. Einstein (Sao
Paulo),
11(1), 128-131.
Verscheure, R. (2017). Influence de
l'utilisation de méthodes alternatives aux pesticides pour lutter contre les
ravageurs de la pomme de terre dans la province du Shandong (Chine).