Table des matières
II. Unité
centrale de calcul (CPU) versus Unité graphique de calcul (GPU)
IV. Compute
Unified Device Architecture (CUDA)
V. Test de performance entre CPU et GPU.
VI.1 Qizhi
Yu et al. Parallel Genetic
Algorithms on Programmable Graphics Hardware.
En informatique, la
programmation parallèle est devenue un outil indispensable, notamment pour des
applications à haut débit. Un algorithme parallèle consiste à partitionner le
problème étudié en tâches élémentaires afin que ces tâches soient exécutées
simultanément dans plusieurs processeurs en vue que le temps d’exécution soit
plus rapide que celui de l’algorithme séquentiel.
L'arrivée des unités graphiques de calcul
(GPUs) programmables rend les cartes graphiques extrêmement intéressantes pour
déporter les calculs sur ces processeurs en permettant un parallélisme massif,
dans un environnement de programmation correcte à bas coût. Il s’agit alors
d’une niche qu'il faut exploiter dans les différentes applications,
particulièrement en bioinformatique.
L’objectif de ce travail consiste à introduire les GPUs en tant qu’une nouvelle plateforme dédiée pour des calculs à haut débit, qui donne lieu à plusieurs applications, tout en montrant leurs avantages dans l’optimisation du temps de calcul.
II. Unité centrale de calcul (CPU) versus Unité graphique de calcul (GPU)
Les processeurs
graphiques sont habituellement destinés aux calculs 3D issus des jeux et aux
applications multimédia. Cependant, ces applications ne constituent qu’une très
faible proportion des tâches attendues de ces processeurs. Les processeurs
graphiques sont considérés alors sous-exploités. Afin de profiter pleinement de
leurs performances, une compagnie appelée NVIDIA à lancer des versions de
cartes graphiques dédiées uniquement pour des calculs de haut débit plutôt que
pour des jeux vidéo. L' utilisation du GPU comme coprocesseur permet également
d’alléger le CPU d'une certaine quantité de travail.
Depuis les cinq
dernières années, le développement des GPUs a connue une évolution
exponentielle comparativement aux CPUs. Cette évolution ne veut pas dire que
les GPUs évoluent plus que les CPUs, mais il s'agirait d’une nouvelle
exploitation des GPUs, plus précisément
dans des calculs intensifs de haut niveau en se basant sur le principe de la
programmation parallèle. L’évolution des GPU et des CPU est illustrée dans la
figure 1.
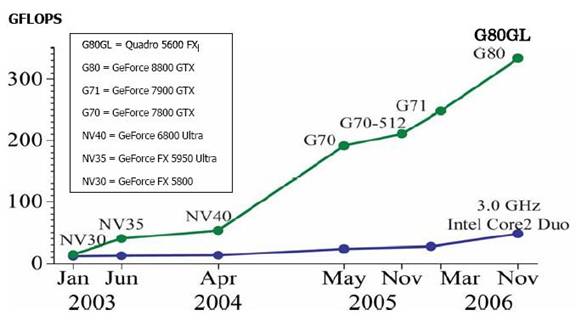
Figure1. Évolution de GPU versus
CPU
Ces deux unités sont alors destinées pour des fins différentes. Ce qu’explique l’attention de priorité accordée au GPU par rapport au CPU. En outre, cette évolution doit être vue comme une multiplication des unités de traitement dans le cas d'un GPU et une complexification des unités de contrôle ainsi qu'une augmentation régulière de la mémoire cache embarquée dans le cas du CPU. Voir la figure 2.
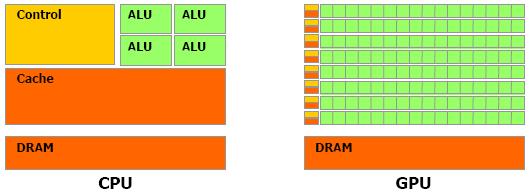
Figure 2. Les deux composants CPU
et GPU
Dans l’ensemble, un
GPU dans sa version GeForce 8800 peut être vu comme une grosse unité de calcul
divisée en 16 multiprocesseurs qui traitent des groupes de 32 threads à travers
8 processeurs généraux et 2 processeurs spécialisés. Ces 16 multiprocesseurs
cadencés permettent ensemble de traiter toutes les instructions courantes sur
512 threads, et avec un débit de 256 opérations par cycle. Le GeForce 8800 a
été décrit comme un GPU équipé de 128 processeurs appelées ALUs répartis en 8
partitions de haute fréquence 1350 MHz.
IV. Compute Unified Device Architecture (CUDA)
Nvidia a mis en disposition un langage et un logiciel de haut niveau appelé Compute Unified Device Architecture (CUDA). Cet outil accompagné d'une documentation détaillée permet d'exploiter les capacités du calcul des GPUs, en se basant sur le principe de programmation parallèle en utilisant des threads. CUDA est un API considéré comme une extension du langage C. CUDA logiciel est composé de trois modules : une interface pour l’application des programmations ‘API’, un runtime qui joue le rôle intermédiaire entre l’utilisateur et le driver et enfin une librairie pour les outils mathématiques.

Figure 3.: Diagramme représentant l’architecture de Compute Unified Device Architecture.
Dans ce qui suit nous
allons expliquer sans rentrer dans les détails, le fonctionnement de CUDA:
- La première étape
consiste à définir la composante sur laquelle le programme va être exécuté.
Cette spécification se fait par un kernel appelé par le CPU et exécuté par le
GPU
- La deuxième étape
est la façon par laquelle le kernel est appelé dans le programme:
Fonction<<< blocks, threads, memory >>>
Tels que les blocs
‘blocks’ représentent le nombre de threads à traiter, threads représentent le
nombre de threads par bloc et memory un espace mémoire optionnel dynamiquement
alloué dans la mémoire partagée, voir la figure 4.
Enfin, une librairie
de fonctions mathématiques est supportée par le GPU telles que les fonctions
d’algèbre linéaire et FFT, et une fonction de synchronisation qui permet de
bloquer l'exécution d'un kernel dans un multiprocesseur tant que tous les
threads ne sont pas arrivés à ce point, de manière à éviter les problèmes de
type lecture après écriture.
Pour exploiter les
performances du GPU, il est essentiel de répartir les tâches sur les grilles
des blocs dont la taille doit être adaptée au problème traité afin de maximiser
l'utilisation des unités de calcul.
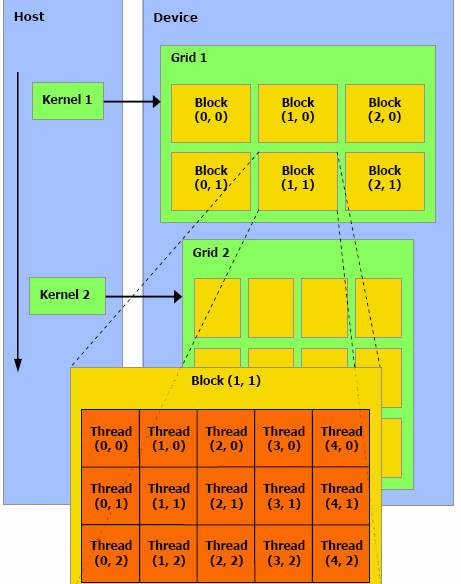
Figure 4. Diagramme représentant le fonctionnement du CUDA
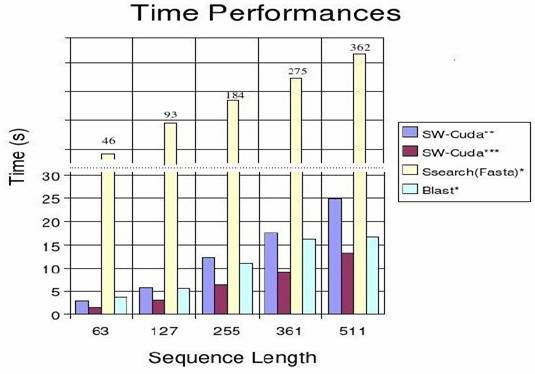
V. Test de performance entre CPU et GPU.
Afin de comparer les
performances du GPU et du CPU en terme de temps de calcul, nous allons
présenter deux exemples qui expliquent la variation de chacune des deux composantes en fonction de deux paramètres,
nombre de blocs et complexité du
problème.
Dans le premier graphique, en fait varier le nombre de blocs et en fixant le nombre d’éléments traités c'est-à-dire, la complexité du problème. Dans le cas du CPU chaque bloc peut être vu comme un thread et donc être exécuté sur un core différent. Sur le CPU, les performances sont identiques quelque soit le nombre de cores,. Dans le cas du GPU, il faut au moins 2 blocs pour qu’il surpasse la performance du CPU. Ensuite, le temps d’exécution décroît jusqu’à 16 blocs pour que les 16 multiprocesseurs soient exploités, et à partir de 32 blocs sa performance demeure identique, du moins pour cet exemple.
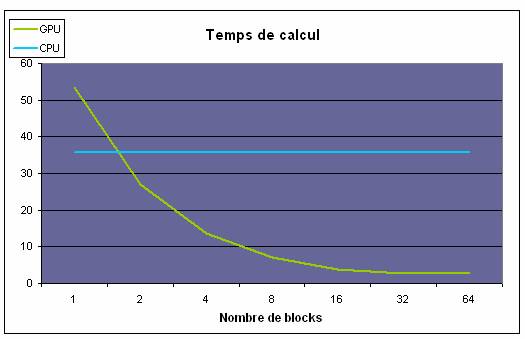
Figure 5. GPU versus CPU en faisant varier le nombre de blocs.
Le second exemple consiste à augmenter la complexité du problème sachant que le nombre de blocs étant fixé à 32. On s’apperçoit que le temps de calcul croît linéairement avec le CPU, contrairement pour le GPU en dessous d'une certaine complexité, ce qui indique que le coût de gestion reste élevé. Il ne suffit donc pas de traiter un nombre élevé de données, mais pour que l’utilisation du GPU soit adéquate, il faut que le problème traité soit suffisamment complexe.
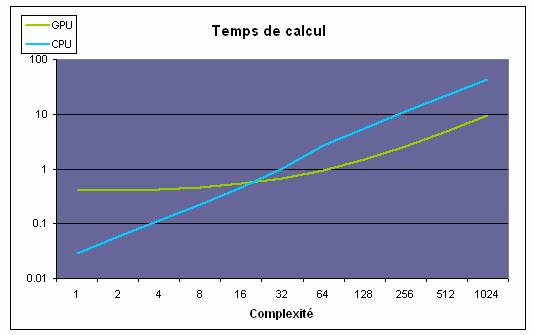
Figure 6. GPU versus CPU en faisant varier la complexité du problème.
VI.1 Qizhi Yu et al. Parallel Genetic
Algorithms on Programmable Graphics Hardware.
Des algorithmes
génétiques parallèles sont habituellement mis en application sur des machines
parallèles ou des systèmes répartis. Ce travail décrit comment des algorithmes
génétiques parallèles à grain fin peuvent être calculés dans l’unité graphique
de calcul. Cette approche consiste à stocker des chromosomes et leurs valeurs
de ‘fitness’ dans une mémoire de texture sur le GPU. L’évaluation de ‘fitness’
et les opérations génétiques sont mises en application entièrement avec des
fragments de programmes exécutés en parallèle sur le GPU. Le graphique
ci-dessous montre l’avantage en terme du temps de calcul pour les algorithmes
génétiques parallèles calculés sur le GPU par rapport au CPU en faisant varier
le taille de populations.
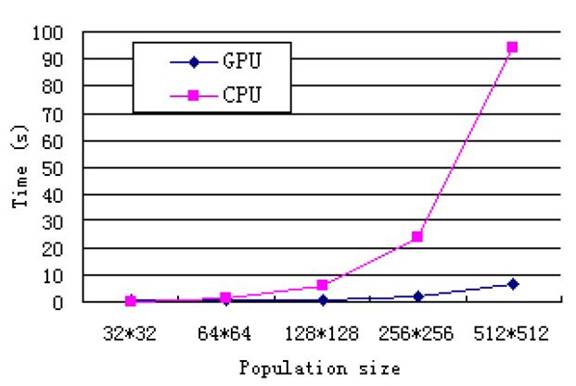
Figure 7. Étude de performance entre GPU et CPU en fonction de taille de population.